AppSwitch を使用した Istio のデイヤリング
AppSwitch を使用したアプリケーションの自動オンボーディングとレイテンシの最適化。
サイドカープロキシのアプローチは、多くの素晴らしいことを可能にします。マイクロサービス間のデータパスに位置するサイドカーは、アプリケーションが何を実行しようとしているかを正確に把握できます。ネットワーク層の奥深くではなく、アプリケーションレベルでプロトコルトラフィックを監視および計測し、詳細な可視性、アクセス制御、トラフィック管理を実現できます。
しかし、よく見てみると、アプリケーショントラフィックの高付加価値分析を実行する前に、データが通過しなければならない中間層が多数存在します。これらの層のほとんどは、データを転送するためだけの基本的な配管インフラストラクチャの一部です。その過程で、通信にレイテンシを追加し、システム全体の複雑さを増します。
長年にわたり、ネットワークデータパスの層内で積極的なきめ細かい最適化を実装するために、多くの共同作業が行われてきました。各反復処理でさらに数マイクロ秒短縮される場合があります。しかし、それらの層自体の真の必要性は疑問視されていません。
層を最適化するのではなく、削除する
私の考えでは、何かを最適化することは、その要件を完全に削除することの貧弱な代替手段です。それは、OSレベルの仮想化に関する私の初期の作業(リンク切れ:https://apporbit.com/a-brief-history-of-containers-from-reality-to-hype/)の目標であり、Linuxコンテナにつながりました。Linuxコンテナは、中間ゲストを必要とせずにホストオペレーティングシステムでアプリケーションを直接実行することで、仮想マシンを効果的に削除しました。長い間、業界はVMを最適化するのではなく、追加レイヤーを完全に削除するという間違った戦いに気を取られていました。
マイクロサービスの接続性、そしてネットワーク全般において、同じパターンが繰り返されているのを目にします。ネットワークは、10年前の物理サーバーが経験した変化を経験しています。新しい層と構造が導入されています。低タッチの代替案を適切に検討することなく、プロトコルスタックやさらにはシリコンに深く組み込まれています。おそらく、これらの追加レイヤーを完全に削除する方法があるでしょう。
私はしばらくの間これらの問題について考えており、コンテナと概念的に類似したアプローチをネットワークスタックに適用することで、多数の中間レイヤーの複雑さを超えてアプリケーションエンドポイントがどのように接続されるかを根本的に簡素化できると考えています。AppSwitchを作成するために、コンテナに関する元の作業と同じ原則を再適用しました。コンテナがアプリケーションが直接消費できるインターフェースを提供する方法と同様に、AppSwitchはアプリケーションが現在使用している明確に定義されたユビキタスなネットワークAPIに直接接続し、アプリケーションクライアントを適切なサーバーに直接接続し、すべての中間レイヤーをスキップします。結局のところ、それがネットワークの本質です。
AppSwitchがIstioスタックから不要なレイヤーを削除する方法の詳細に入る前に、そのアーキテクチャについて簡単に紹介しましょう。詳細はドキュメントページをご覧ください。
AppSwitch
コンテナランタイムと同様に、AppSwitchはREST APIを介してHTTPで通信するクライアントとデーモンで構成されています。クライアントとデーモンはどちらも、自己完結型のバイナリ`ax`として構築されています。クライアントは透過的にアプリケーションに接続し、ネットワーク接続に関連するシステムコールを追跡し、デーモンに発生を通知します。例として、アプリケーションがKubernetesサービスのサービスIPに対して`connect(2)`システムコールを実行するとします。AppSwitchクライアントはconnectコールをインターセプトし、無効化し、システムコールの引数を含むコンテキストとともに、デーモンに発生を通知します。デーモンはシステムコールを処理し、アプリケーションに代わってアップストリームサーバーのPod IPに直接接続する可能性があります。
AppSwitchクライアントとデーモンの間でデータが転送されないことに注意することが重要です。データのコピーを回避するために、Unixドメインソケットを介してファイル記述子(FD)を交換するように設計されています。また、クライアントは別のプロセスではないことにも注意してください。むしろ、アプリケーション自体のコンテキスト内で直接実行されます。アプリケーションとAppSwitchクライアントの間にもデータコピーはありません。
スタックのデイヤリング
AppSwitchの機能がわかったので、標準のサービスメッシュから最適化して削除するレイヤーを見てみましょう。
ネットワークの非仮想化
Kubernetesは、実行するマイクロサービスアプリケーションにシンプルで明確に定義されたネットワーク構造を提供します。ただし、それらをサポートするために、基盤となるネットワークに特定の要件を課します。これらの要件を満たすことはしばしば容易ではありません。要件を満たすために、別のレイヤーを追加するという解決策が一般的に採用されています。ほとんどの場合、追加レイヤーはKubernetesと基盤となるネットワークの間に位置するネットワークオーバーレイで構成されます。アプリケーションによって生成されたトラフィックはソースでカプセル化され、ターゲットでカプセル化解除されます。これはネットワークリソースを消費するだけでなく、計算コアも占有します。
AppSwitchは、プラットフォームとのタッチポイントを通じてアプリケーションが認識するものを調整するため、オーバーレイと同様に、データパスに沿って追加の処理レイヤーを導入することなく、基盤となるネットワークの一貫した仮想ビューをアプリケーションに投影します。コンテナと比較するために、コンテナの内部はVMのように見え、感じられます。ただし、基盤となる実装は、低レベルの割り込みなどの高頻度の制御パスに介入しません。
AppSwitchは、アプリケーションのネットワークが下のネットワークオーバーレイをバイパスしてAppSwitchによって直接処理されるように、標準のKubernetesマニフェスト(Istioインジェクションと同様)に挿入できます。詳細については、もう少しお待ちください。
コンテナネットワークのアーティファクト
ホストからコンテナへのネットワーク接続の拡張は、大きな課題でした。その目的のために、新しいネットワーク配管層が発明されました。そのため、コンテナ内で実行されているアプリケーションは、ホスト上の単なるプロセスです。ただし、アプリケーションが期待するネットワーク抽象化とコンテナネットワーク名前空間によって公開される抽象化の根本的な不整合により、プロセスはホストネットワークに直接アクセスできません。アプリケーションはネットワークをソケットまたはセッションの観点から考えますが、ネットワーク名前空間はデバイスの抽象化を公開します。ネットワーク名前空間に配置されると、プロセスは突然すべての接続を失います。vethペアとその対応するツールリングの概念は、そのギャップを埋めるために発明されました。データはホストインターフェースから仮想スイッチに、次にvethペアを介してコンテナネットワーク名前空間の仮想ネットワークインターフェースに移動する必要があります。
AppSwitchは、接続の両端にある仮想スイッチとvethペアの両方のレイヤーを効果的に削除できます。接続はホストで既に利用可能なネットワークを使用してホストで実行されているデーモンによって確立されるため、ホストネットワークをコンテナにブリッジするための追加の配管は必要ありません。ホストで作成されたソケットFDは、ポッドのネットワーク名前空間内で実行されているアプリケーションに渡されます。アプリケーションがFDを受信するまでに、すべての制御パス作業(セキュリティチェック、接続確立)は既に完了しており、FDは実際のIOの準備ができています。
コロケートされたエンドポイントのTCP / IPをスキップする
TCP / IPは、ほとんどすべての通信が発生する普遍的なプロトコル媒体です。しかし、アプリケーションエンドポイントが同じホスト上にある場合、TCP / IPは本当に必要でしょうか?結局のところ、かなりの量の作業を行い、非常に複雑です。Unixソケットはホスト内通信用に明示的に設計されており、AppSwitchはコロケートされたエンドポイントのUnixソケットを介して通信が透過的に切り替わるようにすることができます。
アプリケーションの各リスニングソケットについて、AppSwitchはTCPとUnixのそれぞれに1つずつ、2つのリスニングソケットを維持します。クライアントがコロケートされているサーバーに接続しようとすると、AppSwitchデーモンはサーバーのUnixリスニングソケットに接続することを選択します。各端にある結果のUnixソケットは、それぞれのアプリケーションに渡されます。完全に接続されたFDが返されると、アプリケーションはそれをビットパイプとして扱います。プロトコルは実際には問題ではありません。アプリケーションは`getsockname(2)`などのプロトコル固有のコールを行う場合があり、AppSwitchはそれらを適切に処理します。アプリケーションが引き続き実行されるように、一貫した応答を提示します。
データプッシュプロキシ
削除するレイヤーを探し続けると、プロキシレイヤー自体の要件も再検討しましょう。プロキシの役割がプレーンデータプッシャーに退化する可能性がある場合があります
- プロトコルデコードは必要ない場合があります
- プロトコルがプロキシによって認識されない場合があります
- 通信が暗号化されており、プロキシが関連するヘッダーにアクセスできない場合があります
- アプリケーション(redis、memcachedなど)はレイテンシに非常に敏感であり、中間プロキシのコストを負担できない場合があります
これらすべての場合において、プロキシは低レベルの配管レイヤーと変わりません。実際、プロキシでは同レベルの最適化が利用できないため、導入されるレイテンシははるかに高くなる可能性があります。
例を挙げて説明するために、以下に示すアプリケーションを考えてみましょう。これは、Pythonアプリとその背後にある一連のmemcachedサーバーで構成されています。アップストリームmemcachedサーバーは、接続時間ルーティングに基づいて選択されます。ここでは速度が最優先事項です。
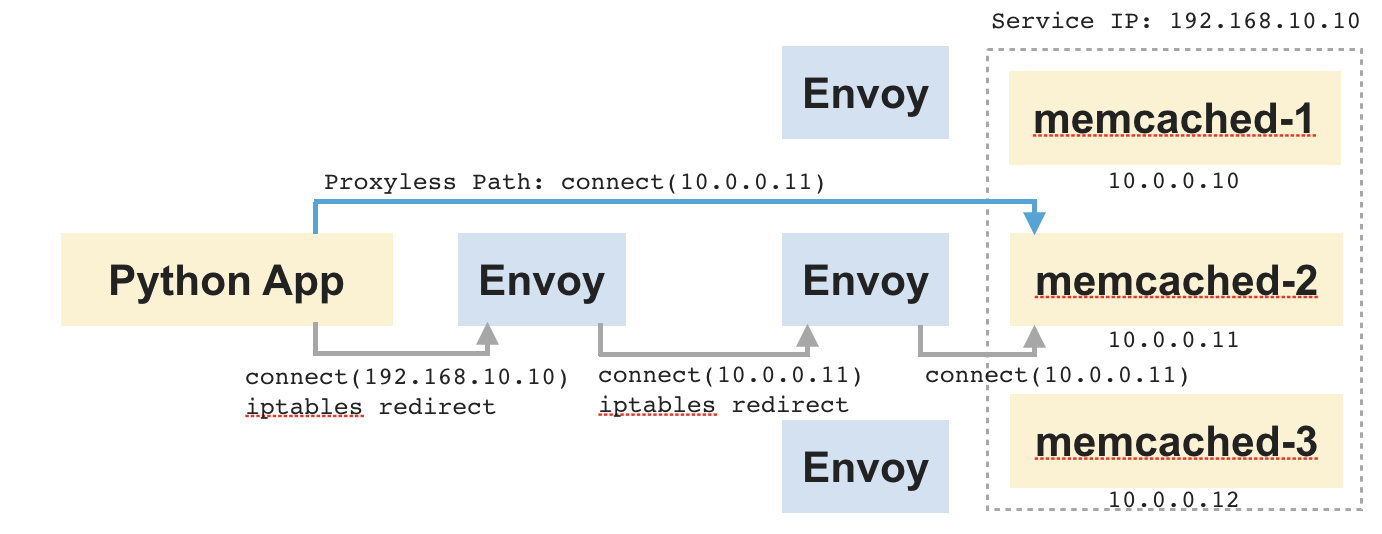
この設定におけるデータフローを見てみると、PythonアプリケーションはmemcachedのサービスIPに接続します。これはクライアントサイドのサイドカーにリダイレクトされます。サイドカーは、接続をいずれかのmemcachedサーバーにルーティングし、2つのソケット(1つはアプリケーションに接続され、もう1つはmemcachedに接続されている)間でデータをコピーします。また、サーバーサイドでも、サーバーサイドのサイドカーとmemcachedの間で同じことが起こります。この時点でのプロキシの役割は、2つのソケット間でビットを退屈にシャベルするだけです。しかし、これはエンドツーエンドの接続にかなりのレイテンシを追加することになります。
ここで、アプリケーションが何らかの方法でmemcachedに直接接続するように設定されていると想像してみてください。すると、2つの中間プロキシをスキップできます。データは、中間ホップなしでアプリケーションとmemcachedの間で直接流れます。AppSwitchは、Pythonアプリケーションが`connect(2)`システムコールを行う際に渡すターゲットアドレスを透過的に調整することで、これを実現できます。
プロキシレスプロトコルデコード
ここからは少し奇妙になります。アプリケーショントラフィックを調べる必要のない場合は、プロキシをバイパスできることを確認しました。しかし、それ以外のケースでもできることはあるでしょうか? 実は、あります。
マイクロサービス間の典型的な通信では、興味深い情報の多くは初期ヘッダーで交換されます。ヘッダーの後には、通常、通信の大部分を占めるボディまたはペイロードが続きます。そして、ここでもプロキシはこの通信部分のデータプッシャーに成り下がります。AppSwitchは、これらのケースでプロキシをスキップするための巧妙なメカニズムを提供します。
AppSwitchはプロキシではありませんが、アプリケーションエンドポイント間の接続を仲介*し*、対応するソケットFDにアクセス*でき*ます。通常、AppSwitchはこれらのFDをアプリケーションに渡すだけです。しかし、ソケットの`recvfrom(2)`システムコールの`MSG_PEEK`オプションを使用して、接続で受信された初期メッセージを覗き見することもできます。これにより、AppSwitchはソケットバッファから実際に削除することなく、アプリケーショントラフィックを調べることができます。AppSwitchがFDをアプリケーションに返し、データパスから外れると、アプリケーションは接続で実際の読み取りを行います。AppSwitchはこの手法を使用して、アプリケーションレベルのトラフィックのより深い分析を実行し、次のセクションで説明するように、データパスに入ることなく、高度なネットワーク機能を実装します。
ゼロコストのロードバランサー、ファイアウォール、ネットワークアナライザー
ロードバランサーやファイアウォールなどのネットワーク機能の典型的な実装では、データ/パケットストリームにタップする必要がある中間層が必要です。たとえば、Kubernetesのロードバランサー(`kube-proxy`)の実装では、iptablesを介してパケットストリームにプローブが導入され、Istioはプロキシレイヤーで同じことを実装します。しかし、ポリシーに基づいて接続をリダイレクトまたはドロップするだけであれば、接続全体を通してデータパスにとどまる必要はありません。AppSwitchは、APIレベルで制御パスを操作するだけで、はるかに効率的に処理できます。アプリケーションに近接しているため、AppSwitchは、スタックとヒープの使用量のダイナミクス、サービスがアクティブになる正確なタイミング、アクティブな接続の属性など、さまざまなアプリケーションレベルのメトリクスに簡単にアクセスできます。これすべてが、監視と分析のための豊富なシグナルを形成する可能性があります。
さらに一歩進んで、AppSwitchはソケットバッファから取得したプロトコルデータに基づいて、L7ロードバランシングとファイアウォール機能を実行することもできます。プロトコルデータとその他のさまざまなシグナルをPilotから取得したポリシー情報と合成して、非常に効率的なルーティングとアクセス制御の適用を実装できます。アプリケーションやその構成を変更することなく、適切なバックエンドサーバーに接続するようにアプリケーションに「影響を与える」ことができます。まるでアプリケーション自体にポリシーとトラフィック管理のインテリジェンスが注入されているかのようです。ただし、この場合、アプリケーションはこの影響から逃れることはできません。
データパスに入ることなくアプリケーションデータストリームを変更できる、さらにいくつかのブラックマジックが可能ですが、それは後の投稿のために取っておきます。AppSwitchの現在の実装では、ユースケースでアプリケーションプロトコルトラフィックの変更が必要な場合は、プロキシを使用します。これらのケースでは、AppSwitchは、次のセクションで説明するように、トラフィックをプロキシに誘導するための非常に最適なメカニズムを提供します。
トラフィックリダイレクション
サイドカープロキシがアプリケーションプロトコルトラフィックを調べることができるようになる前に、最初に接続を受信する必要があります。アプリケーションに出入りする接続のリダイレクションは、現在、パケットをそれぞれのサイドカーに送られるように書き換えるパケットフィルタリングの層によって行われています。リダイレクションポリシーを表すために必要な、潜在的に多数のルールを作成するのは面倒です。また、サイドカーによってキャプチャされるターゲットサブネットが変更されるにつれて、ルールを適用および更新するプロセスはコストがかかります。
パフォーマンスに関する懸念事項のいくつかはLinuxコミュニティによって対処されていますが、権限に関連する別の懸念事項があります。iptablesルールは、ポリシーが変更されるたびに更新する必要があります。現在のアーキテクチャでは、すべての特権操作は、実際のアプリケーションの特権がドロップされる前に、ごく初期に一度だけ実行されるinitコンテナで実行されます。iptablesルールの更新にはroot権限が必要なため、アプリケーションを再起動せずにこれを行う方法はありません。
AppSwitchは、root権限なしでアプリケーション接続をリダイレクトする方法を提供します。そのため、非特権アプリケーションはすでに任意のホスト(ファイアウォールルールなどを除く)に接続することができ、アプリケーションの所有者は、追加の権限を必要とせずに、アプリケーションが`connect(2)`を介して渡すホストアドレスを変更できる必要があります。
ソケット委任
AppSwitchがiptablesを使用せずに接続をリダイレクトする方法を見てみましょう。アプリケーションが何らかの方法で通信に使用するソケットFDをサイドカーに自主的に渡すと、iptablesは必要ありません。AppSwitchは、まさにそれを行う*ソケット委任*と呼ばれる機能を提供します。これにより、サイドカーは、アプリケーション自体を変更することなく、アプリケーションが通信に使用するソケットFDのコピーに透過的にアクセスできます。
Pythonアプリケーションの例では、これを達成するための一連の手順を以下に示します。
- アプリケーションは、memcachedサービスのサービスIPへの接続リクエストを開始します。
- クライアントからの接続リクエストはデーモンに転送されます。
- デーモンは、事前に接続されたUnixソケットのペアを作成します(`socketpair(2)`システムコールを使用)。
- ソケットペアの一方の端をアプリケーションに渡し、アプリケーションがそのソケットFDを読み取り/書き込みに使用できるようにします。また、接続プロパティを照会するすべての呼び出しを仲介することで、アプリケーションがそれを常に期待どおりに正当なTCPソケットとして認識するようにします。
- もう一方の端は、デーモンがAPIを公開する別のUnixソケットを介してサイドカーに渡されます。アプリケーションが接続しようとしていた元の宛先などの情報も、同じインターフェースを介して伝達されます。
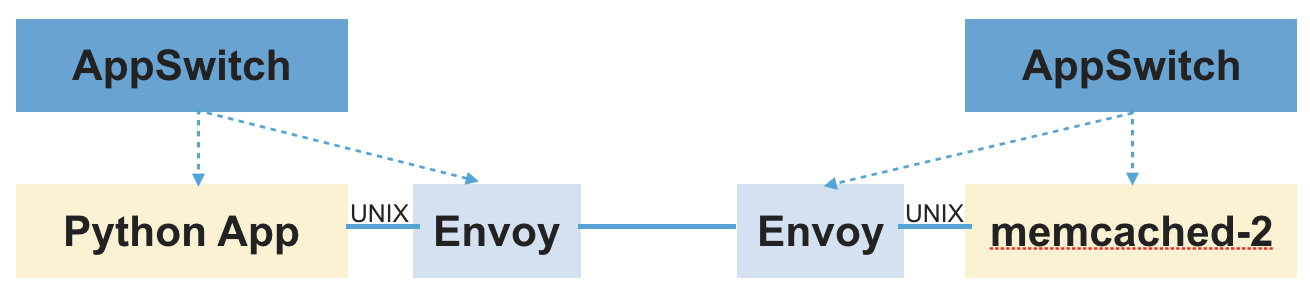
アプリケーションとサイドカーが接続されると、残りは通常どおりに進みます。サイドカーはアップストリームサーバーへの接続を開始し、デーモンから受信したソケットとアップストリームサーバーに接続されたソケットの間でデータをプロキシします。ここでの主な違いは、サイドカーが通常のケースのように`accept(2)`システムコールを介してではなく、Unixソケットを介してデーモンから接続を取得することです。通常の`accept(2)`チャネルを介してアプリケーションからの接続をリッスンするだけでなく、サイドカープロキシはAppSwitchデーモンのRESTエンドポイントに接続して、その方法でソケットを受信します。
完全を期すために、サーバー側で発生する一連の手順を以下に示します
- アプリケーションが接続を受信する
- AppSwitchデーモンは、アプリケーションに代わって接続を受け入れる
- `socketpair(2)`システムコールを使用して、事前に接続されたUnixソケットのペアを作成する
- ソケットペアの一方の端は、`accept(2)`システムコールを介してアプリケーションに返される
- アプリケーションに代わってデーモンによって最初に受け入れられたソケットとともに、ソケットペアのもう一方の端がサイドカーに送信される
- サイドカーは2つのソケットFD(アプリケーションに接続されたUnixソケットFDとリモートクライアントに接続されたTCPソケットFD)を抽出する
- サイドカーは、リモートクライアントに関するデーモンによって提供されたメタデータを読み取り、通常の操作を実行する
「サイドカー対応」アプリケーション
ソケット委任機能は、サイドカーを明示的に認識し、その機能を活用したいアプリケーションにとって非常に役立ちます。同じ機能を使用してソケットをサイドカーに渡すことで、ネットワークインタラクションを自主的に委任できます。ある意味で、AppSwitchはすべてのアプリケーションを透過的にサイドカー対応アプリケーションに変えます。
これらはすべてどのように連携するのでしょうか?
少し戻りますが、Istioは、アプリケーションから共通の接続に関する懸念事項を、アプリケーションに代わってそれらの機能を実行するサイドカープロキシにオフロードします。そして、AppSwitchは、中間層を回避し、本当に必要な場合にのみプロキシを呼び出すことで、サービスメッシュを簡素化し、最適化します。
このセクションの残りの部分では、非常に大まかな初期実装に基づいて、AppSwitchをIstioと統合する方法の概要を説明します。これは設計ドキュメントのようなものではなく、考えられるすべての統合方法が検討されているわけでも、すべての詳細が worked outされているわけでもありません。目的は、実装の高レベルな側面について説明し、2つのシステムがどのように連携するかについての概要を示すことです。重要なのは、AppSwitchがIstioと実際のリモートプロキシの間のクッションとして機能することです。サイドカープロキシを呼び出さずに、より効率的に実行できるケースの「ファストパス」として機能します。また、プロキシが使用される場合は、不要な層を削減することでデータパスを短縮します。統合の詳細な手順については、このブログをご覧ください。
AppSwitch クライアントインジェクション
Istio のサイドカーインジェクターと同様に、ax-injector と呼ばれるシンプルなツールが、AppSwitch クライアントを標準の Kubernetes マニフェストに注入します。注入されたクライアントは、アプリケーションを透過的に監視し、アプリケーションが生成するコントロールパスネットワーク API イベントを AppSwitch デーモンに通知します。
AppSwitch CNI プラグインを使用する場合、インジェクションを必要とせず、標準の Kubernetes マニフェストで作業することが可能です。その場合、CNI プラグインは初期化コールバックを受け取るときに必要なインジェクションを実行します。ただし、インジェクターを使用することにはいくつかの利点があります。(1) GKE のような厳密に制御された環境で動作する (2) Mesos のような他のフレームワークをサポートするように簡単に拡張できる (3) 同じクラスターで標準アプリケーションと「AppSwitch 対応」アプリケーションを一緒に実行できる。
AppSwitch DaemonSet
AppSwitch デーモンは、DaemonSet として実行するか、アプリケーションマニフェストに直接注入されるアプリケーションの拡張機能として実行するように構成できます。いずれの場合も、サポートするアプリケーションから送信されるネットワークイベントを処理します。
ポリシー取得のためのエージェント
これは、Istio によって指示されたポリシーと構成を AppSwitch に伝えるコンポーネントです。Pilot からリッスンするために xDS API を実装し、適切な AppSwitch API を呼び出してデーモンをプログラミングします。たとえば、istioctl で指定されたロードバランシング戦略を、同等の AppSwitch 機能に変換することができます。
AppSwitch「自動キュレーション」サービスレジストリのためのプラットフォームアダプター
AppSwitch はアプリケーションのネットワーク API のコントロールパスにあるため、クラスター全体のサービスのトポロジにすぐにアクセスできます。AppSwitch は、アプリケーションとそのサービスが行き来するにつれて自動的かつ(ほぼ)同期的に更新されるサービスレジストリの形式でその情報を公開します。Kubernetes、Eureka などと並んで AppSwitch の新しいプラットフォームアダプターは、アップストリームサービスの詳細を Istio に提供します。これは厳密には必要ありませんが、上記の AppSwitch エージェントが Pilot から受信したサービスエンドポイントを関連付けることを容易にします。
プロキシの統合と連鎖
アプリケーショントラフィックのディープスキャンとミューテーションを必要とする接続は、前述のソケット委任メカニズムを介して外部プロキシに渡されます。これは、プロキシプロトコルの拡張バージョンを使用します。プロキシプロトコルでサポートされている単純なパラメーターに加えて、さまざまな他のメタデータ(ソケットバッファーから取得した初期プロトコルヘッダーを含む)とライブソケット FD(アプリケーション接続を表す)がプロキシに転送されます。
プロキシはメタデータを見て、どのように処理するかを決定できます。プロキシを実行するために接続を受け入れるか、AppSwitch に接続を許可して高速パスを使用するか、接続を単にドロップするように指示することで応答できます。
このメカニズムの興味深い側面の1つは、プロキシが AppSwitch からソケットを受け入れると、そのソケットを別のプロキシに委任できることです。実際、それが AppSwitch の現在の動作方法です。シンプルな組み込みプロキシを使用してメタデータを調べ、接続を内部で処理するか、外部プロキシ(Envoy)に渡すかを決定します。同じメカニズムを拡張して、それぞれが特定のシグネチャを探し、チェーンの最後のものが実際のプロキシ作業を行うプラグインのチェーンを許可することもできます。
パフォーマンスだけではありません
データパスに沿った中間層を削除することは、パフォーマンスの向上だけではありません。パフォーマンスは素晴らしい副作用ですが、副作用です。API レベルのアプローチには、多くの重要な利点があります。
アプリケーションの自動オンボーディングとポリシーオーサリング
マイクロサービスとサービスメッシュが登場する前は、トラフィック管理はロードバランサーによって行われ、アクセス制御はファイアウォールによって実施されていました。アプリケーションは、比較的静的な IP アドレスと DNS 名で識別されていました。実際、それはほとんどの環境で現状のままです。このような環境は、サービスメッシュから大きな恩恵を受けることができます。ただし、新しい世界への実用的でスケーラブルな橋渡しを提供する必要があります。変革の難しさは、機能の不足によるものではなく、アプリケーションインフラストラクチャ全体を再考し、再実装するために必要な投資によるものです。現在、ポリシーと構成のほとんどは、ロードバランサーとファイアウォールルールという形式で存在します。サービスメッシュモデルを採用するためのスケーラブルなパスを提供するには、既存のコンテキストを何らかの形で活用する必要があります。
AppSwitch は、オンボーディングプロセスを大幅に簡素化できます。ターゲットのアプリケーションに、現在のソース環境と同じネットワーク環境を投影できます。ここで支援がないことは、通常、静的 IP アドレスまたは特定の DNS 名がハードコードされた複雑な構成ファイルを持つ従来のアプリケーションの場合、開始できません。AppSwitch は、既存の構成とともにこれらのアプリケーションをキャプチャし、変更を加えることなくサービスメッシュに接続するのに役立ちます。
より幅広いアプリケーションとプロトコルのサポート
HTTP は明らかに最新のアプリケーション環境を支配していますが、従来のアプリケーションと環境について話すと、あらゆる種類のプロトコルとトランスポートに遭遇します。特に、UDP のサポートは避けられません。IBM WebSphere などの従来のアプリケーションサーバーは、UDP に大きく依存しています。ほとんどのマルチメディアアプリケーションは UDP メディアストリームを使用します。もちろん、DNS はおそらく最も広く使用されている UDP「アプリケーション」です。AppSwitch は TCP とほぼ同じ方法で API レベルで UDP をサポートし、UDP 接続を検出すると、プロキシに委任するのではなく、「高速パス」で透過的に処理できます。
クライアント IP の保持とエンドツーエンドの原則
ソースネットワーク環境を保持するのと同じメカニズムで、サーバーから見えるクライアント IP アドレスも保持できます。サイドカープロキシが配置されていると、接続リクエストはクライアントではなくプロキシから送信されます。その結果、サーバーから見える接続のピアアドレス(IP:ポート)は、クライアントではなくプロキシのアドレスになります。AppSwitch は、サーバーがクライアントの正しいアドレスを確認し、正しくログに記録し、クライアントアドレスに基づいて行われた決定が有効なままであることを保証します。より一般的には、AppSwitch はエンドツーエンドの原則を保持しますが、これは、真の基盤となるコンテキストを不明瞭にする中間層によって破られます。
暗号化されたヘッダーへのアクセスによるアプリケーションシグナルの強化
暗号化されたトラフィックは、サービスメッシュがアプリケーショントラフィックを分析する機能を完全に損ないます。API レベルの介在は、それを回避する方法を提供する可能性があります。AppSwitch の現在の実装では、システムコールレベルでアプリケーションのネットワーク API にアクセスできます。ただし、原則として、アプリケーションデータがまだ暗号化されていないか、すでに復号化されているスタックの上位にある API 境界でアプリケーションに影響を与えることができます。最終的に、データは常にアプリケーションによってクリアで生成され、その後、送信される前にある時点で暗号化されます。AppSwitch はアプリケーションのメモリコンテキスト内で直接実行されるため、データがまだクリアに保持されているスタックの上位でデータをタップすることが可能です。これが機能するための唯一の要件は、暗号化に使用される API が明確に定義され、介在に適していることです。特に、アプリケーションバイナリのシンボルテーブルへのアクセスが必要です。明確にするために、AppSwitch は今日これを実装していません。
それで、ネットは何ですか?
AppSwitch は、標準のサービスメッシュスタックから多くのレイヤーと処理を削除します。パフォーマンスの面で、これはすべて何に変わるのでしょうか?
前述の AppSwitch の初期統合に基づいて、最適化の機会の程度を特徴付けるために、いくつかの初期実験を実行しました。実験は、fortio-0.11.0、istio-0.8.0、および appswitch-0.4.0-2 を使用して GKE で実行されました。プロキシレステストの場合、AppSwitch デーモンは Kubernetes クラスターで DaemonSet として実行され、Fortio ポッド仕様は AppSwitch クライアントを注入するように変更されました。セットアップに加えられた変更はこれら2つだけでした。テストは、100の同時接続にわたる GRPC リクエストのレイテンシを測定するように構成されました。
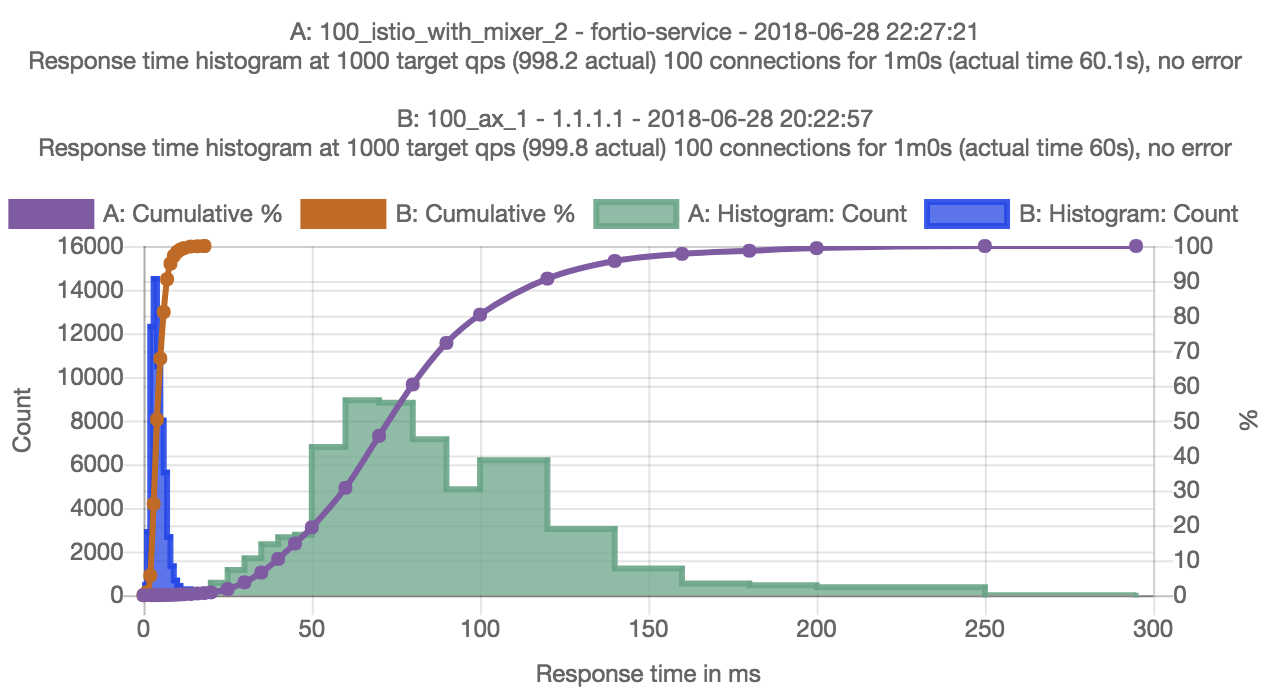
初期の結果は、AppSwitch の有無にかかわらず p50 レイテンシで 18 倍以上の差があることを示しています(3.99 ミリ秒対 72.96 ミリ秒)。ミキサーとアクセスログが無効になっている場合、差は約 8 倍でした。明らかに、この違いは、データパスに沿ったすべての中間層を回避したためです。クライアントポッドとサーバーポッドが別々のホストにスケジュールされていたため、AppSwitch の場合、Unix ソケットの最適化はトリガーされませんでした。クライアントとサーバーが同じ場所に配置されている場合、AppSwitch ケースのエンドツーエンドのレイテンシはさらに低くなります。基本的に、Kubernetes クラスターのそれぞれのポッドで実行されているクライアントとサーバーは、GKE ネットワークを介して TCP ソケットを介して直接接続されます。トンネリング、ブリッジ、またはプロキシはありません。
ネットネット
私は、別の層を追加することは多すぎる層の問題の解決策ではないという David Wheeler の一見合理的な引用から始めました。そして、私はブログのほとんどを通して、現在のネットワークスタックにはすでに多すぎる層があり、それらを削除する必要があると主張しました。しかし、AppSwitch 自体が層ではないでしょうか?
はい、AppSwitch は明らかに別の層です。ただし、他の複数の層を削除できる層です。そうすることで、新しいサービスメッシュ層と従来のネットワーク環境の既存の層をシームレスに接着します。サイドカープロキシのコストを相殺し、Istio が 1.0 に移行するにつれて、既存のアプリケーションとそのネットワーク環境がサービスメッシュの新しい世界に移行するための橋渡しを提供します。
おそらく Wheeler の引用は次のように読むべきです
謝辞
Istio に対する AppSwitch の価値について何度か議論してくださった Mandar Jog(Google)と、このブログの初期の草稿をレビューしてくださった以下の個人(アルファベット順)に感謝します。
- Frank Budinsky (IBM)
- Lin Sun (IBM)
- Shriram Rajagopalan (VMware)


